
Google Alerts: Marktbewegungen, Wettbewerber und Trends im Blick behalten
Wer im Online-Marketing arbeitet, weiß: Märkte verändern sich ständig. Wettbewerber bringen neue Produkte auf den Markt, Unternehmen veröffentlic... mehr

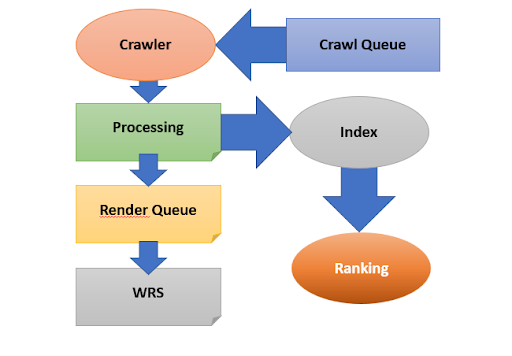
Bei einem Crawler handelt es sich um ein Programm, mit dessen Hilfe Webinhalte aufgerufen und ausgelesen werden können. Google unterscheidet bei seinen Crawlern zwischen zwei verschiedenen Arten: Ein Crawler für die Desktop-Version und ein Crawler für die Mobile-Version einer Website. Mit der Umstellung auf Mobile First Indexing, kommen die meisten Anfragen des Google Bots über den mobilen Crawler, weshalb eine optimierte Website für mobile Endgeräte besonders wichtig ist.
Wissenswert:
Sobald neue Webseiten erstellt und der Suchmaschine zugänglich gemacht wurden, dauert es einige Zeit, bis sie von Google Crawlern besucht werden – Stichwort: Crawling Queue. Sobald der Google Crawler eine Webseite besucht, landet sie im Processing.
Google liest rein in HTML erstellte Webseiten aus und schickt sie durch die externe und/oder interne Verlinkung gefundenen Seiten in den Crawling Queue, damit diese erneut ausgelesen werden können.
Wissenswert: Handelt es sich um eine Internetseite, die dynamische Inhalte aufweist (z. B. Javascript), dann wird sie in das sogenannte Render Queue gesteckt, bis das Rendering (WRS) abgeschlossen ist. Ist das Rendering bzw. Processing abgeschlossen, beginnt die Indexierung.
Das Crawling reicht nicht aus, damit eine Webseite in der organischen Suche zu finden ist. Während des Processings kommt es zur Verarbeitung der Inhalte (HTML-Content, statische Inhalte z. B. Bilder, CSS-Dateien usw.).
Wissenswert:
Tipp: Damit es dem Suchmaschinenbot möglich ist, alle Inhalte zu erkennen bzw. zu interpretieren, solltest du ein Crawling aller Webseiten-Assets erlauben.
Während des Indexierungsprozesses erfolgt die Aufnahme der gefundenen Infos in den Index. Man kann sagen, über die vielen Jahre ist praktisch eine riesige Wissensdatenbank bzw. Online Bibliothek entstanden. Sobald ein User den gewünschten Begriff (Keyword) ins Suchfeld eingibt, filtert Google im Index die Infos heraus, die am besten zu den verwendeten Keywords passen.
Wissenswert:
Ja, es ist möglich, die Indexierung zu kontrollieren. Du hast die Möglichkeit, dem Spider vorzugeben, welche Inhalte gecrawlt, aber nicht indexiert werden sollen – Stichwort: De-Indexierung mit Meta-noindex.
Seiten, die aus dem Index ausgeschlossen werden sollten, sind z. B. paginierte Seiten. Diese entstehen z. B. durch eine interne Suche. Diese Seiten haben keine einzigartigen Inhalte bzw. Mehrwert zu bieten und sind dadurch für die Suchmaschine nicht relevant.
Wissenswert:
Tipp: Um das Crawling-Budget nicht unnötig zu belasten, sollten die Seiten von der Indexierung ausgeschlossen werden, die du nicht als relevant erachtest.
Werden Seiteninhalte aktualisiert und Veränderungen gespeichert, bekommen Besucher der Webseite die aktuelle Variante zu sehen. Der Spider hat aber von den Änderungen noch überhaupt keine Ahnung. Der Bot erfährt erst von den Neuerungen, wenn die Internetseite erneut gecrawlt wird. Das wiederholte Crawlen einer Webseite passiert ganz automatisch. Es kann aber einige Zeit dauern, bis das passiert.
Da Index und Ranking eng miteinander verknüpft sind, ist es ratsam, dem Spider mitzuteilen, dass es Änderungen gegeben hat. In der Regel geht die Indexierung einer Webseite reibungslos vonstatten. Jedoch kann es manchmal etwas dauern, bis sich die Änderungen auch im Suchindex (10 Min – 3 Stunden) bemerkbar machen.
Die Gründe, warum eine Webseite nicht in den Index aufgenommen wird, sind vielfältig, wie z. B.

